大模型的文案工作流程
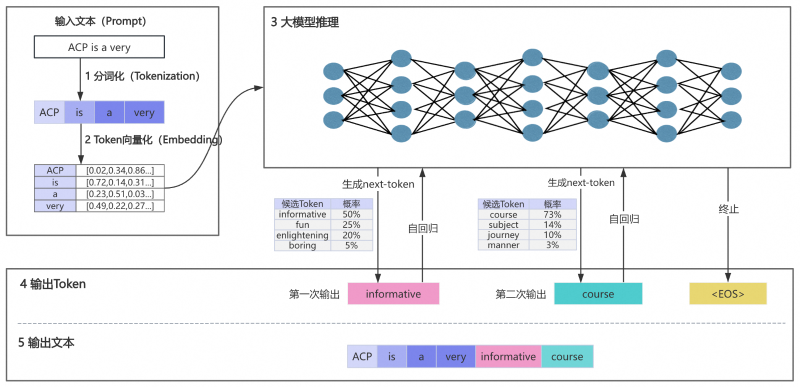
- 第一阶段:输入文本分词化
- 第二阶段:Token向量化
- 第三阶段:大模型推理
- 第四阶段:输出Token
- 第五阶段:输出文本
影响大模型内容生成的随机性参数
关键参数
temperature:调整候选Token集合的概率分布
在大模型生成下一个词(next-token)之前,它会先为候选Token计算一个初始概率分布。这个分布表示每个候选Token作为next-token的概率。temperature是一个调节器,它通过改变候选Token的概率分布,影响大模型的内容生成。通过调节这个参数,你可以灵活地控制生成文本的多样性和创造性。
- 明确答案(如生成代码):调低温度。
- 创意多样(如广告文案):调高温度。
- 无特殊需求:使用默认温度(通常为中温度范围)。
需要注意的是,当 temperature=0 时,虽然会最大限度降低随机性,但无法保证每次输出完全一致。
top_p:控制候选Token集合的采样范围
top_p 是一种筛选机制,用于从候选 Token 集合中选出符合特定条件的“小集合”。具体方法是:按概率从高到低排序,选取累计概率达到设定阈值的 Token 组成新的候选集合,从而缩小选择范围。
- 值越大 :候选范围越广,内容更多样化,适合创意写作、诗歌生成等场景。
- 值越小 :候选范围越窄,输出更稳定,适合新闻初稿、代码生成等需要明确答案的场景。
- 极小值(如 0.0001):理论上模型只选择概率最高的 Token,输出非常稳定。但实际上,由于分布式系统、模型输出的额外调整等因素可能引入的微小随机性,仍无法保证每次输出完全一致。
参数调优
是否需要同时调整temperature和top_p? 为了确保生成内容的可控性,建议不要同时调整top_p和temperature,同时调整可能导致输出结果不可预测。你可以优先调整其中一种参数,观察其对结果的影响,再逐步微调。
RAG评测相关概念与指标
-
召回质量 (Retrieval Quality): RAG系统是否检索到了正确且相关的文档片段?
-
答案忠实度 (Faithfulness): 生成的答案是否完全基于检索到的上下文,没有“胡编乱造”(幻觉)?
-
答案相关性 (Answer Relevance): 生成的答案是否准确地回答了用户的问题?
-
上下文利用率/效率 (Context Utilization/Efficiency): 大模型是否有效地利用了所有提供给它的上下文信息?
-
Ragas的评估指标,整体回答质量的评估: Answer Correctness,用于评估 RAG 应用生成答案的准确度。
-
生成环节的评估: Answer Relevancy,用于评估 RAG 应用生成的答案是否与问题相关。 Faithfulness,用于评估 RAG 应用生成的答案和检索到的参考资料的事实一致性。
-
召回阶段的评估: Context Precision,用于评估 contexts 中与准确答案相关的条目是否排名靠前、占比高(信噪比)。 Context Recall,用于评估有多少相关参考资料被检索到,越高的得分意味着更少的相关参考资料被遗漏。
熟悉 RAG 的工作流程
RAG(Retrieval Augmented Generation,检索增强生成)是一种结合了信息检索和生成式模型的技术,能够在生成答案时利用外部知识库中的相关信息。它的工作流程可以分为几个关键步骤:解析与切片、向量存储、检索召回、生成答案等。
Agent 五种工作流模式
- 流水线
- 分支选择
- 并行执行
- 混合专家
- 人机协作
如何选择
核心原则:没有“最好”的模式,只有“最适合”的模式。你的选择应该由任务的内在属性决定,例如任务的复杂度、子任务间的依赖关系、对成本和效率的要求,以及对结果质量和风险的容忍度。
- 单体 Agent 的局限性:追求“全能”的单个 Agent 在处理需跨多个专业领域的复杂任务(如课程开发)时,往往会因知识边界和认知负荷而表现不佳。
- 多智能体的核心思路:从僵化的“流水线”模式的失败中,你受到现实世界高效团队的启发,认识到“专业分工、并行处理、沟通整合”是解决复杂问题的关键。
- 多智能体协作模式:你掌握了两种主流的协作模式。分层规划模式通过模拟“项目主管-专家”的结构,高效处理可清晰拆解的任务;共创协作模式则通过模拟“头脑风暴”,在开放式问题上激发集体智慧。
成本与价值的权衡:虽然多智能体系统会增加调用成本和延迟,但它通过提高最终产出的“可用性”,避免了因低质量输出而导致的重复尝试和隐性成本,是一种对高质量结果的有效投资。
一个优秀的 Agent 系统,并非某种单一的先进技术,而是两条互补路线的结合:
工程化的可控自治路线:深入理解业务场景,将现实世界高效的流程与评价原则,转化为 Agent 的工作流与评测体系,并通过上下文工程精细控制每一个环节,在明确边界内发挥模型的“单兵能力”,构建起一个可靠、可控的 Agent 工程系统。这是战略与战术层面的“工程基座”。
开放式的自主进化路线:在这个工程基座之上,在同一套评测与反馈机制的约束和指引下,引入自主规划和多智能体协作,让 Agent 不再只是被动执行预设流程,而是能够围绕目标自行规划、分工协作并产生涌现行为,在保证可控性的前提下,逐步提升系统的整体智能上限。这是面向未来的“智能进化”。
